{kind=link}
{kind=link}


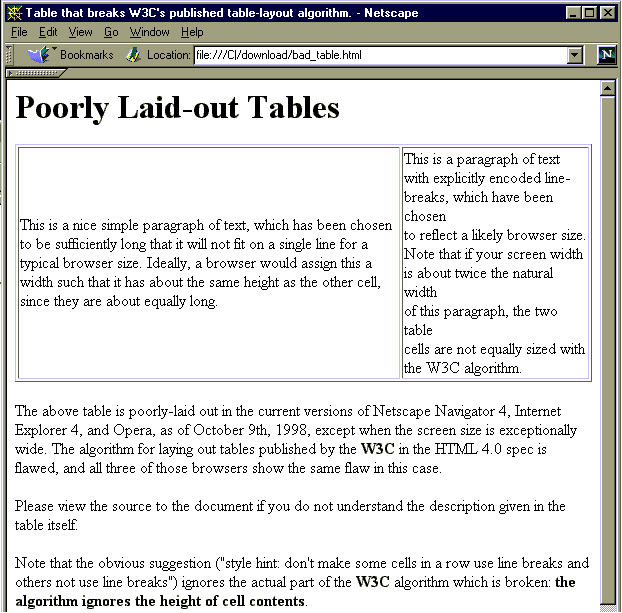
| This is a nice simple paragraph of text, which has been chosen to be sufficiently long that it will not fit on a single line for a typical browser size. Ideally, a browser would assign this a width such that it has about the same height as the other cell, since they are about equally long. |
This is a paragraph of text with explicitly encoded line- breaks, which have been chosen to reflect a likely browser size. Note that if your screen width is about twice the natural width of this paragraph, the two table cells are not equally sized with the W3C algorithm. |
The above table is poorly-laid out in the current versions of Netscape Navigator 4, Internet Explorer 4, and Opera, as of October 9th, 1998, except when the screen size is exceptionally wide. The algorithm for laying out tables published by the W3C in the HTML 4.0 spec is flawed, and all three of those browsers show the same flaw in this case.
Please view the source to the document if you do not understand the description given in the table itself. For those who cannot see the "badness", on Netscape, with the browser set to anywhere between 2x and 3x the "natural width" of the right paragraph, the right paragraph is not given sufficient width, and additional line wraps are introduced. (At 2x, it needs to split in half, since the two have approximately equal area.)
Note that the obvious suggestion ("style hint: don't make some cells in a row use line breaks and others not use line breaks") ignores the actual part of the W3C algorithm which is broken: the algorithm ignores the height of cell contents.
Proper cell-layout minimizes whitespace. If two cells are competing for space, and each cell uses roughly the same area, then they should be laid out with the same width (if they are both relatively reflowable). The W3C algorithm can be interpreted as using the ratio of maximum width/minimum width as an approximation to the height of the cell contents, or, more explicitly, using maximum width as an approximation to the area of the cell contents. This is an incorrect approximation in the presence of cells with different heights, but will work correctly if all cell contents have the same minimum height.
The example chosen in the above table is merely a simple way of constructing cell contents with identical area, but varying heights, thus breaking the equal-height assumption in the above formulation. Note, however, that the presence of line-breaks limits the reflowability of the text, and in the presence of such quantization, a fast algorithm cannot achieve "perfect" quantization. However, even without explicitly modelling the reflowability of the text, it seems plausible that a better heuristic is efficiently computable; for example, one which computes the height necessary for both minimum- and maximum- width display of each table cell and factors this into the 'area estimate'.
Here is another example. Note that the data is sufficiently quantized that whitespace-free display is impossible unless you resize your browser perfectly. However, a "good" layout algorithm will try to split the table roughly in half. Netscape Navigator 4 does if you make the browser width a little more than 16 images wide; Internet Explorer 4 and Opera do not. The published W3C algorithm will behave like IE4 and Opera.
|
|
|
Similar effects can be achieved using any height-varying mechanism, such as different sizes of fonts. However, the flaw is exacerabated by very large variations in content height; the first table uses a height ratio of 9:1, and the second 4:1.
Note: I refer to this layout algorithm as "the W3C" algorithm because it has been published without further attribution in the HTML 4.0 specification. It is contained in appendix B, in the "Notes on Tables" section, where it is called the "Autolayout Algorithm". It is not normative, but appears in a section titled "Recommended Layout Algorithms", and the purpose of this article is to dispute that recommendation.
Update 2007-02: It turns out the original source of this algorithm is RFC 1942.
Update 2007-09:
In September 2007, Peter Moulder at Monash University
pointed me at some work he and others have done about this and
related issues:
home : sean at nothings dot org