
Numerous claims about Judy's performance are made in the Judy whitepaper. I don't think any of those claims are wrong. However, it does not appear that sufficient effort was put in benchmarking Judy against other data structures. Now, it is unlikely there is another data structure that is both as fast and as small as Judy is. But it is easy to come away from reading about Judy getting the impression that because it is small (and hence more cache-friendly), it will be faster than something larger. (For example, look at the discussion about "tunnelling under" the time/space trade-off curve.) This is not necessarily the case; if in the end what matters is performance, the only thing to do is measure performance, not space.
There are a few potential disadvantages to keep in mind about the Judy approach. Its author argues that approaching the problem as engineering means accepting that complexity is how you get good performance; simplicity is for theoreticians. But this complexity leads to things like a data structure with 20,000 lines of code designed on the assumption that a cache-line is 64 bytes being used primarily on machines with 32-byte cache lines; a redesign optimized for 32-byte cache lines would come close to starting from scratch.
Additionally, some of Judy's space and speed improvements come from strategies that could be used by any data structure but aren't because they're not good software engineering. Most abstract data types give you a fixed pointer good for the life of that datatype; Judy omits one level of indirection and gives you a pointer that may change during the life of the associative array as it grows and shrinks; if you want multiple objects to have pointers to the same Judy array, you'll need to wrap the changing-pointer in another data structure--just like how data structures are normally. Judy saves space by encoding information in the bottom bits of the pointer; this would interfere with any other use of the bottom bits, e.g. in a language that uses tagged boxed data like OCaml.
The Judy white paper mentions comparisons to hash tables, but from the description they appear to have tested fixed-size hash tables with external chaining. Such structures have performance O(N) with a very small constant, 1/M where M is the size of the hash table. Proper hash tables have performance O(1). For this comparison, I wrote a hash table data type with the same interface as JudyL, an associative array type whose key and value are both 32 bits.
I used a hash table with secondary hashing (internal chaining), using a table size of a power of two that periodically doubles, rehashing all the elements. The arbitrary doubling threshhold I picked for the initial implementation was 65% full, and although I included a command-line option for tuning it I never did. For the first time in my life I also wrote code that causes the table to shrink by a factor of two; the default here is if it gets under 30% full. (The difference between 65% and 2*30% is intentional, to avoid hash-table-resize thrashing.) Also, the hash table rehashes all the elements if the table reaches 80% full of real entries and deleted markers. (On deletion in a hash table with internal chaining, you have to leave a marker that allows you to keep probing past the deletion. With repeated insertions and deletions, the table might become full of deletion markers and have very poor performance.)
For full compatibility with Judy, two values were chosen as "out of band", to represent 'empty' and 'deleted' slots in the hash table. The main data structure that keeps data about the hash table contains two boolean flags for whether the corresponding keys are currently in the associative array, and two values representing their associated values if so, so that those keys will never appear in the hash table "legitimately" and are thus safe to use "out of band". (Traditionally, hash tables are often hashing pointers and can use NULL pointers or misaligned pointers as out-of-band values.)
I put some effort into trying to "early out" of the hash table routines quickly; for example, if the first probe is a hit, the secondary hash value is never computed.
The hash table implementation is about 200 lines of C code, and can be read here. I used Bob Jenkin's mix function which is designed to intermix three 32-bit values at a time; probably overkill for a single 32-bit value, but it means there's pretty much no plausible data that doesn't hash well.
I originally compiled Judy under Win2K with MSVC 6, but migrated to Win98 for final testing. I did not attempt to use any of the supplied makefiles or such, and manually constructed compiler directives instead. In a few cases this required making copies of some files that are compiled twice, because I couldn't find any way to convince the MSVC IDE to compile them multiple times otherwise. After moving to Win98, I had to change the Judy memory allocator to allocate an additional 16 bytes on every allocation, and leave eight bytes on either side as padding; presumably this is due to bugs in the Win98 memory allocator. (I had to do something similar to my hash table allocator, but I never tested that under Win2K and it might just be a bug in my code.) The total number of lines of code in "JudyCommon" (double-counting the two duplicated files described above), according to "wc -l *.c": 23,850
The performance comparison was run on a Dell laptop with a 700Mhz Pentium III processor. The machine had 512MB of memory, but exhibited a small amount of disk activity on the largest tests, despite only requiring around 128MB to store the largest data structure, even after repeated runs to "warm" the machine. (This odd choice for a test machine is simply because it is my primary home machine. People are welcome to repeat the tests on other platforms, and I'll be happy to link to the results.)
A single application included Judy, the hash table implementation, and the test bed. This application is implemented in a single C file, which should be completely portable except for the single function at the end which reports the current time (which is here implemented for Win98 only). It does not include the Judy source code, which must be built and linked separately.
The test bed itself runs repeated tests on differing sizes of tables, using various datasets. The original version ran each test three times and reported the fastest version, to avoid random glitches, but in the end this was removed since the tests were running far too slowly. It turns out that sufficient sample points are gathered that any glitching will cause a visible outlier in the data which is easily ignored, and in fact it rarely happens in practice on this machine.
DOS batch files were used to generate all the sample data; they should be able to be converted to shell scripts without much trouble. (hash.bat, judy.bat, both.bat, build.bat, probe.bat)
(There is a little sloppiness in the results reported below. This is due to the fact that this data collection process took too long and I had to give up before I was able to get everything perfect.)
Judy is more space efficient than the hash table, but not astonishingly so. The hash table at its fullest is 65% full, so uses 8/0.65 bytes per key/value pair, or roughly 12 bytes. Judy is usually a bit better. However, immediately after doubling the hash table uses twice as much storage for essentially the same number of keys, so on average and in the worst case Judy is quite a bit smaller. (This effect will be less significant with larger associated values.)
When looking up data, Judy is slower for very large data structures (1M+ entries) if the data is random, and faster if it isn't. (This isn't because the hash table is bad at non-random data, but because Judy is good at it.) For smaller data structures, the hash table is a tad faster. The hash table is always faster for updating (insertion and deletion without changing the overall size of the data structure). Time to build a data structure by repeated insertions are similar to lookup-time.
I want to make sure you understand why I use the particular mode of graphing I do, so I'm going to illustrate some poor choices first. We'll use as the example data the time taken to build an associative array of a given size, which is probably the least important data to be presented here.
The x-axis in the above graph is the number of insertions; the vertical axis is the time taken in milliseconds. Because the graph isn't logarithmic, it is dominated by the very large data structures; the first x-axis tic mark is at 2,000,000 items.
Let's look at a log-log graph instead, to try to preserve detail across the board.
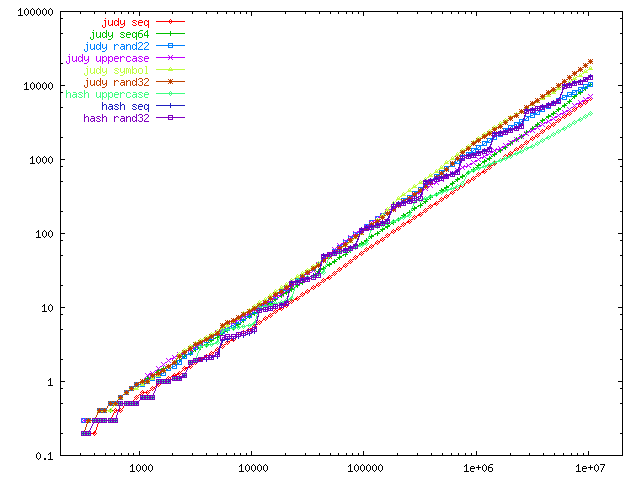
Now we can see all the data points, but because the graph is dominated by the exponential growth of the time (due to exponential growth in the number of insertions), there's really no way to read the data.
Instead, we use a logarithmic x-axis, and for the y-axis, we switch from total time to "time per operation"; in this case, milliseconds per insertion during the build phase. (To make sure this is unambiguous, relative to the first graph above, this graphs y/x [dependent] vs. log(x) [independent].)

Here you can see the data is much more readable, so this is the format all the graphs will be in. The y-axis will always extend down to 0, so something which is twice as high as something else will always mean it is slower by a factor of 2.
Now let's interpret the data.
In each tooth, the jump upwards represents a point where the table size doubled, and extra time was spent rehashing. Then the average time per insertion starts dropping again as the insertion happens without triggering rehashes. You can see that the sawtooth stays roughly level for the left third of the graph, and then rises. It begins rising at the rehash at around 20K elements, meaning when the hash table grows from 32K to 64K elements. Each hash table entry requires 8 bytes, so this indicates the table has grown from 256K to 512K. This might mean that the secondary cache is only 256K on this machine. (There's another hidden table being used, the table of precomputed keys to insert, which is traversed as the table is built. This will cause some cache conflicts, but hopefully not too many, especially as it is 4-bytes per key and traversed linearly with perfect cacheing.)
The line also behaves erratically below 10000, but this appears to be due to glitchy data (a single continuously growing build was used to capture all the samples, so a single glitch affected all samples, but became inconsequential as more time was spent). Also, the total time for under 2000 entries was 1.0 ms, and the output routine only displays one place after the decimal (despite measuring it much more precisely, oops), so the low end data is all rather suspect. (Note that I did something different for the rest of the performance timings, so this mistake only matters for this graph.)
Both seq and seq64 do not start at 0; they start at some arbitrarily large number I've forgotten that has non-zero values in every byte.
I also tested some other seq amounts, but they all behaved similarly. Seq64 is probably not the best choice, since it will result in Judy leaves of exactly 4 elements, which happens by chance to be stored in one 32-byte cache line.
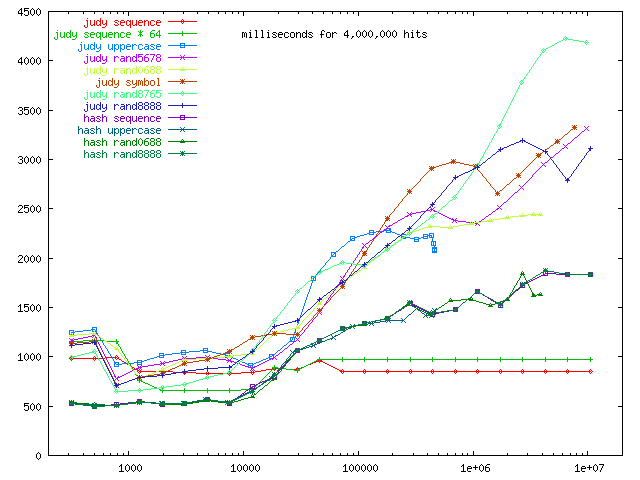
Overall, hash table performance is strictly superior to Judy for under 10,000 items. Beyond that, hash table performance slows (as mentioned before, presumably due to secondary cacheing effects). Judy on sequential data maintains the same performance regardless of size, and is superior beyond 20,000 entries (on this machine, and tuning the hash table might change this crossover point). However, the hash table is strictly superior on all the random data presented here, generally by a factor of 2.
rand8888 is random 32-bit numbers. rand0688 is random 22-bit numbers. rand5678 is random numbers where the high byte has 5 random bits, and the low byte has 8 random bits, for a total of 22 random bits. rand8765 is similar, but byte-swapped.
Note that the judy uppercase ends in a tail; the extra points correspond to number of insertions that would fall further to the right, but the data points are marked based on the actual number of entries in the table. As Judy goes from nearly-full (of random data) to full, its performance increases slightly (but does not come anywhere close to the sequential result).
As might be expected from the nature of Judy, rand8765 has the worst performance. I spent a lot of time trying to find a dataset on which Judy would behave better than on the random data, but worse than the sequence data. This included building the table with sequential data that had been shuffled, or using sequential-by-some-4-digit-prime, or using a "jittered" sequence; while this code is in the codebase, I did get around to graphing any of it and I'm not sure where that middleground lies. Clearly rand8765 is effectively just constructed to be a worst-case for Judy, and probably isn't likely to ever occur in real life.
Curiously, judy seq64 is consistently faster than judy seq in the 2,000 - 10,000 region, but they are reversed above 50,000.

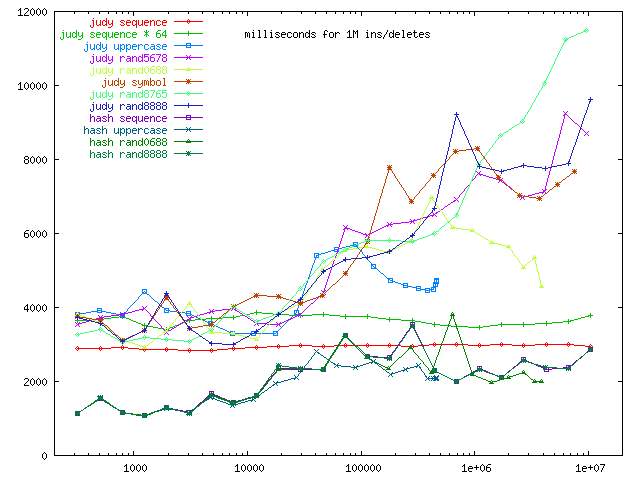
We can make a simple prediction of what we'd expect this graph to look like compared to the hit graph, based on the way the algorithms work.
Judy uses a tree in which any key has exactly one place it might exist, whether it's present or not; the time to find a key should be the same, whether a hit or a miss. The hash table uses a chain of entries threaded through the table of all items with the same hash key, and does what is effectively a linear probe of those. A miss requires searching the whole list; a hit will on average require searching half the list, so we expect miss times for the hash table to be about twice the hit times.
This is roughly born out in the actual data. In practice, though, with the hash table as sparse as it is, miss times are not actually twice as slow, but more like 1.3 to 1.6 the speed. As a result, the hash table miss times are still competitive with Judy below 10,000 entries, and similar to Judy for random numbers all the way up the scale. Judy gets a big lead for the step-by-64 arithmetic sequence. In the special case of the increment-by-1-sequence, there aren't any values you can probe that lie between two values present in the table; anything that misses must be smaller than or larger than every other entry in the table. As a result, judy seq misses always probe off either the left or right end of the table, and as a result, it should end up with all the necessary data in the primary cache. You can see this in the results for judy seq from 30,000 to 7,000,000; the last data point might be a glitch. I don't know why it's not faster below 20,000.
The following graph is a closeup of the left half of the above graph.
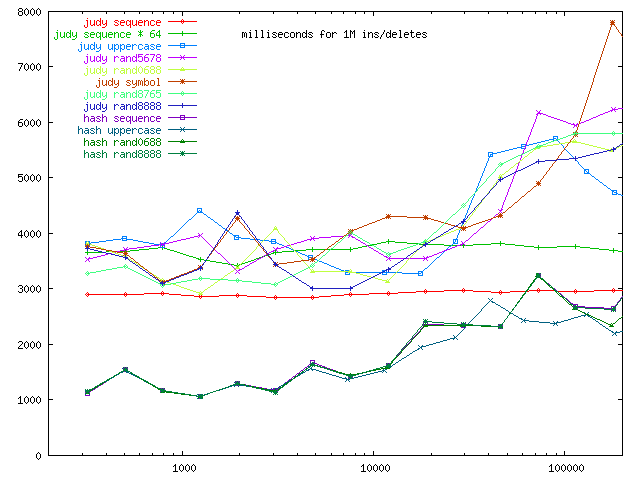
Optimized insertions and deletions were apparently not a focus of Judy; the hash table is fairly efficient. (Insertions correspond to misses, and deletions to hits, but this graph doesn't look like the average of those two, so more is going on.) The hash table rehash logic is unlikely to be triggered here (except for the rehash-if-too-many-deletes) due to the intentional mismatch of the doubling and halving threshhold. (Perhaps the too-many-deletes is being triggered, and this accounts for the spikiness of the graph in the hundreds-of-thousands; I don't know.) But as I showed in the first graph, the hash table does perform competitively on raw-insertions, even with the cost of rehashing on doubling. So in general insertion & deletion are a win for the hash table.
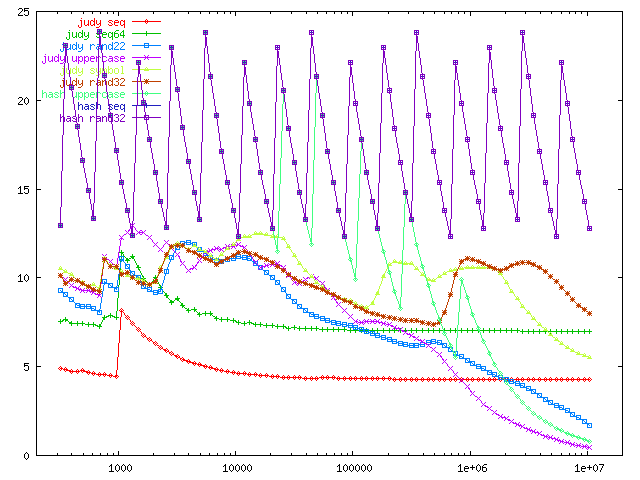
Judy is way smaller than the hash table. In the best case, with sequential data, Judy uses about 5 bytes--4 of which are required to store the value, so effectively only 1 byte per key. That grows rapidly to 7 bytes for seq64. (The curves which drop down at the right don't count--this is again a case of graphing memory vs. number of insertions instead of memory vs. total number of entries.) Meanwhile the hash table best case uses the worst case memory of Judy (around 12 bytes), and worst case uses 24.
As illustrated in this data, Judy's smaller size does not give it an enormous speed advantage over a traditional "trade size for speed" data structure. Judy has received countless man-hours developing and debugging 20,000 lines of code; I spent an hour or three writing a fairly standard 200-line hash table.
If your data is strictly sequential; you should use a regular array. If your data is often sequential, or approximately sequential (e.g. an arithmetic sequence stepping by 64), Judy might be the best data structure to use. If you need to keep space to a minimum--you have a huge number of associative arrays, or you're only storing very small values, Judy is probably a good idea. If you need an sorted iterator, go with Judy. Otherwise, a hash table may be just as effective, possibly faster, and much simpler.
Furthermore, there aren't many ways to improve Judy, but there's a lot of room to improve hash tables. The one tested here is just my standard "classic" hash table. I don't know what best practice really is these days. For example, Knuth describes numerous strategies for hashing to allow the table to be more full. Using a prime table size would allow rehashing to grow by, say, 25% instead of 100%, reducing storage overhead. There's already a strategy for incrementally growing a hash table a single slot at a time, explictly amortizing what is effectively size-doubling. (Although this is kind of silly since you don't want to realloc() the data structure one item at a time, to avoid O(N2) cost. In fact, realloc() may automatically use doubling under the hood--in which case you might as well expose the memory to the hash table.) Alternately, we can reconsider hash tables on the basis of cache usage. For example, in the testbed source code is a second hash table implementation: a bucketed hash. This is a hash table in which every 32-byte cache line is a bucket of four key/value pairs; this allows the equivalent of four probes with only one cache line load. My experiments showed this slightly improved miss times, but made little other difference; however, more tuning of the doubling threshhold might have made more difference (it might be wise to then let the table get more full).
One could also Judy-ize hash tables--allowing null pointers to represent empty tables, and storing very small tables (under 16 entries, say), specially, possibly using the bottom bits to tag the special cases. You could probably do pretty well using only another 100 lines of code.
Of course, you can certainly take the attitude that Judy performs well enough, and the fact that it's 20,000 lines of code doesn't really matter, as long as those lines of code work and you never have to look at them--and it appears Judy is mature enough that this is the case.
It bugs me, though.
Sean Barrett, 2003-08-01
sean at nothings dot org