Once upon a time, the World Wide Web was going to be this awesome democratizing "everyone publishes, everyone reads" medium--a giant international bulletin board. Sure, most people just posted pictures of their cat. The power law meant some Mahirs and dancing hamsters were more popular than others. But there was something really neat about this idea.
Nowadays, most people seem to consider that web dead, save for blogs.
For a while I've wanted to rant about the way I think the W3C has killed the web, but I've been sitting on it for probably a year, because, to be honest, I know nothing about the W3C and the web standardization process (other than the fact that they didn't seem open to public comment in 1998—hence, six years later, browsers still lay tables out poorly). However, I just discovered that browser developers started publically griping about the W3C themselves back in June 2004. David Baron of Mozilla wrote: "[I] believe that the W3C is no longer the primary organization to which we should look for future standardization on the Web." Ian Hickson of Opera commented before a W3C workshop (he doesn't seem to have summed it up quite as well afterwards)
I'm very much at a loss as to what to expect from this workshop. On the one hand I really can't see us convincing everyone else that the solution is to continue down the HTML path. After all, it's not in the interests of most of the other attendees. Many of them are wanting to sell SVG, XForms, or XHTML products, and most of those who aren't are probably more concerned with developing a good theoretical solution than addressing the unfortunate pragmatic needs of today's authors.
The W3C is a consortium of the sorts of attendees Hickson describes.
Brendan Eich (also of Mozilla) summarized the W3C cleverly with the title of this blog post: The non-world non-wide non-web.
The sad fact is that the w3c is not concerned with the world wide web, AKA the Internet. Rather, the focus for a while now seems to be on vertical tool/plugin and service/cellphone markets, where interoperation is not a requirement, content authors are few and paid by the vertical service provider, and new standards provide livelihoods and junkets for a relative handful of academics, standards body employees, and big company implementors.
That should be enough to give you a sense of what the W3C is up to.
Fortunately, these guys are not all talk and no action. They have turned around and given us the WHAT Working Group, "a loose unofficial collaboration of Web browser manufacturers and interested parties who wish to develop new technologies designed to allow authors to write and deploy Applications over the World Wide Web."
That seems a pretty clear mandate, right? Applications over the WWW, in clear contrast to the W3C's vertical intranet model. Hickson elaborates in his blog (if you have to skip, read the last paragraph at least, and hover):
Then again, I work for a browser vendor, and have been in the browser industry (both voluntarily and as a job) for years now. So it's not surprise that I think the browser is important as an application platform. (Obviously, though, as Robert Scoble is eager to tell us, Web apps aren't the answer to everything. I wouldn't recommend to anyone that they try to write a graphics manipulation package in HTML.)The problem with the browser today is that applications based in the browser are constrained to nightmarish UI idioms and a severe lack of polish stemming from the fact that the platform was not really developed as a platform, and that no real progress has been made on this path for several years.
John Gruber points out that users don't really seem to care about the poor UI, though. The other advantages — especially the true zero-install cost of Web-based applications — far outweigh the costs.
But that's why we started WHATWG: we want to make it easier to make nicer the kinds of applications that it makes sense to deploy over the Web. Mail and news clients. Cinema ticket sales. Book stores. Auction sites. Multiplayer stategy games.
(Links and markup from original.)
Hickson's really throwing down the gauntlet here. Clearly there are two sorts of uses a browser can be put to
In a later blog entry he hedges, seemingly believing that they might as well tweak work they do improving #2 so it helps #1 as well:
Something I hadn't realised until recently is quite how many Web applications are hidden away inside intranet sites. I always knew that there were some there, but the sheer numbers of such applications is quite surprising. A few people have sent me confidential screenshots of their intranet applications (with the sensitive parts censored, of course), which has really helped get me an idea of the kinds of features that would be most helpful to people writing such sites.
He doesn't really explain this desire, but I don't think it's really anything sinister or inconsistent.
Now, all of these posts are about web applications, so technically the fact that they only mention web applications isn't a fault, but there are enough comments about the Web in general and about browsers in general that I pretty much feel justified in asking: what about #3? You know, the part where people post documents and other people read them, as opposed to web applications of flavors 1 or 2? As C J Silverio observed a long time ago (in a rant coincidentally titled the same as this one), "The net is precious to me because it gives ordinary human beings a way to communicate with other ordinary human beings. Corporations have too many ways to cram their ads down my throat. Human beings have the net."
I get the feeling that browser authors feel it's ok to focus on things like web applications because case #3 is well in hand, what with CSS to give nice pretty presentation and all. There's nothing they can do about the all-important content--that's up to the individual authors.
And yes, they can't change the content, can't make it suck less. But there's a lot they can do about my interaction with that content!
This is why the web sucks, but you just don't know it. It sucks because your experience interacting with the web could be vastly better, but browser authors are instead caught up in enhancing the abilities of content creators to enhance your experience, instead of directly enhancing your experience. Yet very little of the stuff the web browser creators are adding comes into play in most of my interaction with the world wide web (as opposed to the non-world non-wide non-web), especially in case #3--plain old documents from average users. Average users having nothing to do with this stuff; as ceej's rant above describes, ability to generate good content has little bearing on ability to generate good presentation.
In fact, individuals writing material for the web these days are probably writing in blogs, posting comments to bulletin boards (using bbcode instead of HTML), and contributing to wikis (with their own custom markup language). In none of these cases will those users directly use features of, say, CSS, much less Web Forms. (The indirect use of CSS in templates as presentation separate from content is pretty much irrelevant in all three of those cases, where HTML is constructed dynamically from a content database anyway. The indirect use of forms for wikis and bulletin boards is obvious, but also not obviously in need of much more than a text area and a submit button.)
Here's a list of major browser standards introduced roughly after Netscape 3 (when I started noticing browser devolution):
On the other hand, we can look at major browser innovations independent of the above (this is based on my experience with Firefox; I haven't tried Opera in four or five years):
Now what I want you to think about is the amount of work browser authors have put into implementing the standards above (which, I claim, primarily improve the ability of content authors to control the appearance and interactivity--though PNG is a special case involving GIF patents), versus the amount of work browser authors put into improving the user-controlled experience of interacting with web pages (in the form of those last two innovations, the first of which is a small improvement on the Windows MDI model, and the latter of which has been in Emacs forever). Now, you might protest "but they do lots of other work for the user experience besides just adding major features", and this is somewhat true, but it's pretty much just about treading water compared to something like NS 3 (that is, the user experience treads water even if making that user experience the same requires a lot of work due to the new standards). And they're going to do that work no matter what; it's not optional. However much work they've put in on such things, I'm arguing we've traded off work on major new features for user-controlled experience in favor of new standards for author-control, even though the reality is that most of the websites I (at least) visit do not use those new standards, or if they do, use them without enhancing my experience (e.g. XHTML), or without significantly enhancing my experience (as in most uses of DHTML; see Appendix A).
To give you a hand thinking about this, let's point out how big the specifications for those standards are. Since pages and lines can be arbitrarily sized, I'm just going to use bytecounts of uncompressed HTML-formatted specs to give us a ballpark understanding. (Some of these are one long file, some are multiple files, which may skew the results somewhat. Don't look at me, this is how the W3C distributes them.)
| 210 KB | HTML 2.0 (RFC 1866 is only 143KB, though) |
| 128 KB | HTML 3.2 |
| 187 KB | CSS1 |
| 1,547 KB | HTML 4.01 |
| 2,131 KB | XHTML 1.0 (72KB) + XML (220KB) + HTML 4.01 (1,839 KB) and not even counting various other specifications like XML namespaces |
| 1,106 KB | CSS2 |
| 638 KB | DOM Level One (2nd ed) |
| 827 KB | DOM Level Two Core + Level Two HTML |
| 313 KB | PNG (2nd ed) |
| 3,886 KB | SVG 1.1 |
Let me highlight a few elements of this. XML, a specification for generic self-delimiting ASCII data files, is nearly twice the size of HTML 3.2, a fairly full-fledged markup language with tables and fonts and everything. SVG 1.1 is 10 times the size of PNG (of course it's quite different; perhaps it would be more relevant to compare the size of the SVG specification to the size of the Flash Player DLL). HTML 4.01 is over 10 times as big as HTML 3.2; CSS2 is almost as big.
What is all of this good for? A lot of what seems to have turned web authors' cranks about CSS has simply been features entirely unavailable in plain HTML, like positioning. Positioning is all about abandoning the old model that authors can't have total control over the layout. It's all about abandoning the idea that different people access a website in different contexts. What this means, of course, is a lot of lousy browsing experience going to web sites where your fonts aren't the size they expect or your web browser is narrower than they expected. (The web browsers naturally honor requests for frames without scrollbars even when they're needed, since the content creator is always right!) I even get to use my handy "zap style sheet" bookmarklet when I reach websites that are theoretically well-designed but in practice unreadable for me simply due to insufficient text contrast. Yes, Virginia. There really are people out there with content worth reading but whose presentation sucks, at least for my poor eyes and tiny screen pixels. (Huh, what? User stylesheets? I have to learn CSS to view the web?)
So not only do these new standards get used rarely, but when they do, a lot of the time they seem to just make things worse on category #3 sites—which makes the effort spent implementing them seem a tad frivolous. (Especially if what you believe is that it's the content that really matters.) Now, in part, CSS was developed in the hopes that web authors would be able to stop having to do browser-specific workarounds to display what they want, but apparently IE's incomplete CSS support hosed this plan. That this surprises anyone surprises me. If you keep evolving the standards, nobody is going to be up to spec! As a result, web designers are basically just as screwed as they were, and people with perfectly functional old web browsers are forced to upgrade to slightly less-functional browsers with better standards support (I only switched from Netscape Navigator 4.08 within the last year). Is anybody happy? I guess the people being paid to implement the new standards.
Some time, a long time ago, the Mozilla developers got it in their head that they were developing an application platform, and they've never lost that drive, and it seems use #3 has long since fallen by the wayside. As a result, real security concerns arise, and we end up with web applications developers from category #1 (I guess) arguing against disallowing 'location=no' when you have to wonder why we even need to give people in category #3--and even people in category #2 who are the imitatees of phishing scams--the ability to download custom XUL. (In fact, a deeper concern this bug advances is that even without XUL, somebody can spoof a fake window in the middle of the client area just using DHTML. Somehow I seem to be the only one in the world who sees this as evidence that providing DHTML over the insecure world of the Internet is itself going too far. Maybe we don't have to be quite so Turing-complete? Does PayPal really prefer to have the option to spiffify their UI at the cost of making life easier for phishers?)
So, look, obviously if what you care about is #1, or even #2, I'm not going to convince you. You can just wander off now, content in the fact that I don't understand the business proposition facing browser authors, or whatever. And sure, I don't. You can argue that maybe we need a whole different class of web browsers for #3-style web page browsing, or just to make fuck-ups like me happy. But those #2-driven browsers create a market in which all browsers must be standards compliant. I'm all for standards compliance in theory, but right now that means all browsers need to implement those 7+MB of features the W3C spewed out while people still considered the W3C relevant, rather than just, say, the 128KB HTML 3.2 specification. (Ok, 7MB includes SVG; even without that, we're still talking 20x the size of HTML 3.2, and probably more than 20x the complexity, since most of this stuff isn't modular the way, say, the Flash plugin is.) This is complicated enough it's nearly impossible to start a new browser from scratch, and even "new browser" efforts like Firefox that build from an open source base like Mozilla turn out to be hemmed in by the original architecture.
It's an interesting experience to read through Bugzilla and discover how hard some things are that obviously are only hard because of the architecture, not because of some inherent problem. For example, some users would like the ability for, say, the file "foo.c" to open in the browser inline, rather than launching out to the OS-configured external application (in my case, a programming IDE): bug #57342. It turns out that Mozilla's file download "stream converter" model has some limitation (last discussed in March 2002) that makes it difficult for the browser to change its mind in the middle of the download from downloading as a file to downloading to the browser. (The problem being that once the stream is seen to be not a type the browser handles internally, it is handed off to a system that pops up a 'do you want to save or open with', and adding the option 'open with browser' there is hard. Yet, clearly, given only that specification and no existing infrastructure, the problem is not at all hard. Parse the stream; if it's not "text/html" or another type handled internally, pause, pop up the window, discover what you should do with it, and go. Mozilla instead has already bailed on internalizing the stream by the time the window pops up, and it's too late to go back.)
Sometimes it's hard to see in Bugzilla what exactly the holdup is. If I want to click an .mp3 link and have the URL be handed to my streaming mp3 player, rather than have it downloaded entirely and then handed over, I am stuck. (Unless, apparently, I use Opera or IE). For Firefox, this is bug 225882: "Ability to pass URLs to helper apps (for streaming) instead of downloading and then passing the entire file." Fixing this bug depends on some "backend work", marked as a dependency on bug 137339: "want way to hand URL to helper apps without downloading whole document first", which I guess is the Mozilla version of this bug--although it's marked OS Linux, and it last received a comment in January 2003. Meanwhile, that bug is marked as depending on bug 90501: "Allow sending URL instead of file to helper app based on content type." (Sound familiar?) Last real comment in January 2003 (save for a dupe report and a "I really want this" comment). The three bugs only have 10, 6, and 2 votes, so they don't get much love. And I believe these sorts of things would have gotten fixed faster if standards-compliance wasn't so complicated. I'd think about fixing these things myself, but Mozilla falls in the realm of code so over-engineered it takes too long to get up to speed to change the tiniest thing. (Possibly this is necessary over-engineering due to the complexity of the problem and the desire for widely distributed programming. But it's an impassable barrier for me to do any casual fixing, and in my estimation it must be a barrier to getting outside contributors.)
Worse yet, Opera and Mozilla and Apple aren't saying, "Goddamn this stuff is just already too complicated. Let's just freeze what we've got and really consider it a standard, so we can just fix all the damn bugs and work on interactivity." Instead, it seems they've bought whole hog into W3C's "what's good for the web is constant generation of new standards", and they're happily generating more and more! Yay! Go content authors, now you can make javascript draw images! Spoofers of the world unite! (If nothing else it's great for Opera, since it raises the barrier to entry for potential competitors. Since the other browsers aren't developed for profit, though, and they're just as gung ho, that's probably not Opera's reasoning either.)
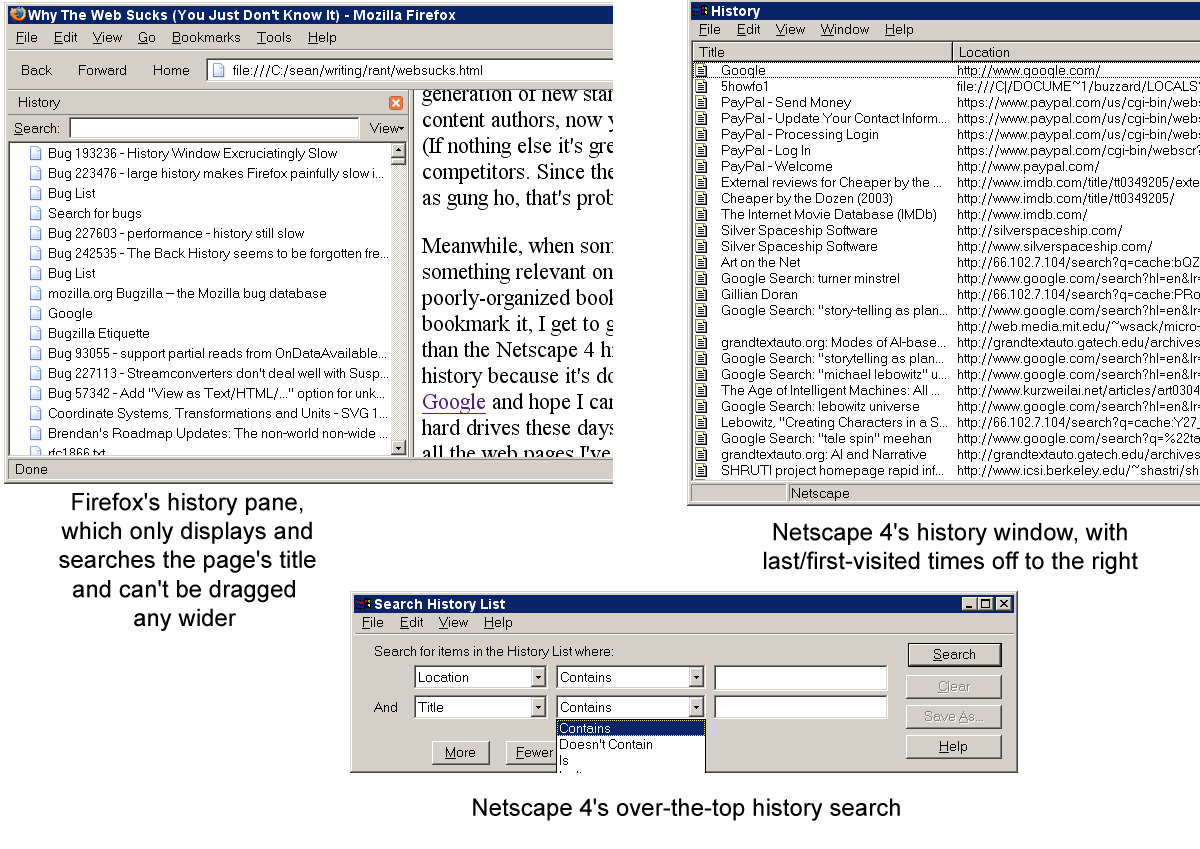
Meanwhile, when someone mentions something to me and I remember having seen something relevant on the web a little while ago, I get to grovel through thousands of poorly-organized bookmarks (missed innovation opportunity) hoping I thought to bookmark it, because if I didn't bookmark it, I get to grovel through my IE-clone "history pane" with less functionality than the Netscape 4 history window (browser devolution due to Firefox's anti-featureism), but it's not there because I only keep 9 days of history because it's dog slow if I keep 90 days much less 730 (18-month-old bug), and then I have to go to Google and hope I can remember something distinctive enough to locate the page again although its Page Rank is low—even though hard drives these days are enormous and why aren't I just full-text searching the text of all the web pages I've visited in the last 90 days (missed innovation opportunity)? 1 2 I don't know, but it seems to be because the blue sky got clouded over by Hurricane WebApp.
1 I actually had to do this while writing this article—except searching on Bugzilla not Google--because I never end up thinking up the right keywords for finding bugs I've seen before. If you're wondering why the link about XUL spoofing didn't actually have any web app devs arguing against 'location=no', it's because I think I saw that somewhere, but I couldn't find the actual bug where I'd seen it.
2This isn't a unique scenario. I'm constantly bumping into these sorts of bugs (misfeatures) and browser devolutions whenever I use Firefox. Some of these show in Bugzilla as new Firefox bugs; some show as ancient, unloved bugs in Mozilla. Many of the obvious possible innovations show up as enhancement requests; who knows how many non-obvious ones we're ignoring? And then there are the devolutions. Some of these are hard to judge, since different people approach the browser with different workflow, and I'm a power user, but I think little issues like this behavior I hate indicate a lack of "big picture" thought about the web-browsing experience in favor of (in this case) pursuit of standards and conventional rules-of-thumb.
Looking at the last 25 pages in my browser history (25 because that's when I got bored--this actually takes a lot of work), I find:
Actually, on further reflection, I guess LiveJournal recently added a new "inline comment" feature that's DHTML, but I wasn't looking at a page with comments.
The following table details most of the sites in my browser
history from the last few days. For each site, I indicate the
type of HTML: HTML 4.01, XHTML 1.0, etc.
(Some pages don't specify a DTD, especially hand-authored
pages.) Also the use of CSS: CSS, inline CSS (no separate
style sheet), CSS (no style use); the
use of SVG: SVG (ok, guess what, there's none); the use of
DHTML/DOM and JavaScript: DHTML, JS.
(I omit JS if it's only used for banner ads, e.g. Google
AdSense, and trivial things like opening comment windows.)
I probably should have made note of pages that used tables
for layout, as almost all of them did (if they did any
layout at all). All sites with XHTML sent it as text/plain.
I also indicate whether it is category 2 (a web-application sort of site) or category 3 (plain documents authored by Joe EndUser), or # for professionally-created plain documents.
I only include one page from each site.
| HTML 4.01 Transitional, inline CSS | 3 | Joel on Software blog-ish |
| HTML 3.2, | #? | Slashdot news summarizer (didn't count JS/CSS from ad) |
| ?, inline CSS, JS | 2 | Google search engine |
| HTML 4.0 Transitional, inline CSS, JS | 2 | LiveJournal webapp blog host (use of style sheets depends on user settings) |
| ?, Flash, | # | BrainWash laundromat |
| ?, JS, | # | RedMeat print comic |
| XHTML 1.0 Strict, CSS | 3 | Grumpy Gamer blog |
| ?, CSS | 3 | Snopes Urban Legends Reference Pages |
| HTML 4.01 Transitional, CSS | 3 | Scary Go Round web comic |
| ?, CSS | # | Internet Movie Database |
| HTML 4.01 Transitional, CSS, JS | 2 | NetFlix DVD rentals |
| XHTML 1.0 Transitional, CSS | 3 | Language Log linguistics blog |
| ?, CSS, JS | # | Washington Post online news |
| ?, CSS, DHTML | # | MSNBC online news |
| ?, CSS, JS | # | The Onion online news parody |
| ?, CSS, JS? | # | Interview with Chuck D & Hank Shocklee of Public Enemy online magazine archive |
| ?, inline CSS, JS | # | Weather Underground weather information |
| XHTML 1.0 Transitional, CSS | 3 | Umami Tsunami blog |
| ?, inline CSS | 3 | Casey Learns to Draw pseudo-blog |
| ?, | 3 | Gmail is too creepy blog spinoff |
| ?, JS, | 3 | Sluggy Freelance webcomic |
| ?, CSS, | # | Log Cabin Republicans political organization press release |
| ?, CSS, JS | # | NVIDIA Developer Web Site hardware vendor developer relations |
| ?, CSS | 3 | RPG Gamer gaming web site |
| XHTML 1.0 Transitional, CSS, DHTML | 2 | Wikipedia online encyclopedia |
| sites below this line were actually earlier in browser history but were visited for the purposes of writing this article, and are omitted from the totals to avoid bias | ||
| ?, CSS | # | Mozilla blue sky |
| XHTML 1.0 Transitional, CSS, JS | 3 | Brendan's Roadmap Update |
| HTML 4.01 Transitional, CSS, JS | 2 | Bugzilla Bug 22183 |
| HTML 4.0, CSS | 3 | Hixie's Natural Log |
| ?, CSS | 3 | Why the web sucks, II |
| XHTML 1.0 Strict, CSS | 3 | David Baron's weblog |
home : sean at nothings dot org
{kind=link}